Lizy's Blog
Happy coding
Linux下Socket编程
网络编程,一定离不开套接口;那什么是套接口呢?在Linux下,所有的I/O操作都是通过读写文件描述符而产生的,文件描述符是一个和打开的文件相关联的整数,这个文件并不只包括真正存储在磁盘上的文件,还包括一个网络连接、一个命名管道、一个终端等,而套接口就是系统进程和文件描述符通信的一种方法。目前最常用的套接口是字:字节流套接口(基于TCP)和数据报套接口(基于UDP),当然还有原始套接口(原始套接口提供TCP套接口和UDP套接口所不提供的功能,如构造自己的TCP或UDP分组)等,我们这里主要介绍字节流套接口和数据报套接口。
要学习网络编程,一定离不开网络库的函数,在Linux系统下,可以用"man 函数名"来得到这个函数的帮助,不过为了照顾E文不大好的朋友,下面就将常用的网络函数和用法列出来供大家参考:
1、socket函数:为了执行网络输入输出,一个进程必须做的第一件事就是调用socket函数获得一个文件描述符。
————————————————————————————-
#include
#include
int socket(int family,int type,int protocol);
返回:非负描述字---成功 -1---失败
————————————————————————————-
第一个参数指明了协议簇,目前支持5种协议簇,最常用的有AF_INET(IPv4协议)和AF_INET6(IPv6协议);第二个参数指明套接口类型,有三种类型可选:SOCK_STREAM(字节流套接口)、SOCK_DGRAM(数据报套接口)和SOCK_RAW(原始套接口);如果套接口类型不是原始套接口,那么第三个参数就为0。
2、connect函数:当用socket建立了套接口后,可以调用connect为这个套接字指明远程端的地址;如果是字节流套接口,connect就使用三次握手建立一个连接;如果是数据报套接口,connect仅指明远程端地址,而不向它发送任何数据。
————————————————————————————-
#include
#include
int connect(int sockfd,const struct sockaddr * serv_addr,int addrlen);
返回:0---成功 -1---失败
————————————————————————————-
第一个参数是socket函数返回的套接口描述字;第二和第三个参数分别是一个指向套接口地址结构的指针和该结构的大小。
这些地址结构的名字均已“sockaddr_”开头,并以对应每个协议族的唯一后缀结束。以IPv4套接口地址结构为例,它以“sockaddr_in”命名,定义在头文件;以下是结构体的内容:
————————————————————————————-
struct in_addr {
unsigned long s_addr; /* IPv4地址 */
};
struct sockaddr_in {
short int sin_family; /* 套接口地址结构的地址簇,这里为AF_INET */
unsigned short int sin_port; /* TCP或UDP端口 */
struct in_addr sin_addr;/*存放ip地址的结构*/
unsigned char sin_zero; /* 无符号的8位整数 */
};
————————————————————————————-
3、bind函数:为套接口分配一个本地IP和协议端口,对于网际协议,协议地址是32位IPv4地址或128位IPv6地址与16位的TCP或UDP端口号的组合;如指定端口为0,调用bind时内核将选择一个临时端口,如果指定一个通配IP地址,则要等到建立连接后内核才选择一个本地IP地址。
————————————————————————————-
#include
#include
int bind(int sockfd,const struct sockaddr *myaddr,int addrlen);
返回:0---成功 -1---失败
————————————————————————————-
第一个参数是socket函数返回的套接口描述字;第二和第第三个参数分别是一个指向特定于协议的地址结构的指针和该地址结构的长度。
4、listen函数:listen函数仅被TCP服务器调用,它的作用是将用sock创建的主动套接口转换成被动套接口,并等待来自客户端的连接请求。
————————————————————————————-
#include
#include
int listen(int sockfd,int backlog);
返回:0---成功 -1---失败
————————————————————————————-
第一个参数是socket函数返回的套接口描述字;第二个参数规定了内核为此套接口排队的最大连接个数。由于listen函数第二个参数的原因,内核要维护两个队列:以完成连接队列和未完成连接队列。未完成队列中存放的是TCP连接的三路握手为完成的连接,accept函数是从以连接队列中取连接返回给进程;当以连接队列为空时,进程将进入睡眠状态。
5、accept函数:accept函数由TCP服务器调用,从已完成连接队列头返回一个已完成连接,如果完成连接队列为空,则进程进入睡眠状态。
————————————————————————————-
#include
#include
int accept(int sockfd,struct sockaddr *iaddr,int *addrlen);
返回:非负描述字---成功 -1---失败
————————————————————————————-
第一个参数是socket函数返回的套接口描述字;第二个和第三个参数分别是一个指向连接方的套接口地址结构和该地址结构的长度;该函数返回的是一个全新的套接口描述字;如果对客户段的信息不感兴趣,可以将第二和第三个参数置为空。
6、inet_pton函数:将点分十进制串转换成网络字节序二进制值,此函数对IPv4地址和IPv6地址都能处理。
————————————————————————————-
#include
int inet_pton(int family,const char * strptr,void * addrptr);
返回:1---成功 0---输入不是有效的表达格式 -1---失败
————————————————————————————-
第一个参数可以是AF_INET或AF_INET6:第二个参数是一个指向点分十进制串的指针:第三个参数是一个指向转换后的网络字节序的二进制值的指针。
7、inet_ntop函数:和inet_pton函数正好相反,inet_ntop函数是将网络字节序二进制值转换成点分十进制串。
————————————————————————————-
#include
const char * inet_ntop(int family,const void * addrptr,char * strptr,size_t len);
返回:指向结果的指针---成功 NULL---失败
————————————————————————————-
第一个参数可以是AF_INET或AF_INET6:第二个参数是一个指向网络字节序的二进制值的指针;第三个参数是一个指向转换后的点分十进制串的指针;第四个参数是目标的大小,以免函数溢出其调用者的缓冲区。
8、fock函数:在网络服务器中,一个服务端口可以允许一定数量的客户端同时连接,这时单进程是不可能实现的,而fock就分配一个子进程和客户端会话,当然,这只是fock的一个典型应用。
————————————————————————————-
#include
pid_t fock(void); 返回:在子进程中为0,在父进程中为子进程ID -1---失败
————————————————————————————-
fock函数调用后返回两次,父进程返回子进程ID,子进程返回0。
有了上面的基础知识,我们就可以进一步了解TCP套接口和UDP套接口
1、TCP套接口
TCP套接口使用TCP建立连接,建立一个TCP连接需要三次握手,基本过程是服务器先建立一个套接口并等待客户端的连接请求;当客户端调用connect进行主动连接请求时,客户端TCP发送一个SYN,告诉服务器客户端将在连接中发送的数据的初始序列号;当服务器收到这个SYN后也给客户端发一个SYN,里面包含了服务器将在同一连接中发送的数据的初始序列号;最后客户在确认服务器发的SYN。到此为止,一个TCP连接被建立。
下面就用一个例子来说明服务器和客户是怎么连接的
————————————————————————————-
/* client.c */
#include
#include
#include
#include
#include
#include /*struct sockaddr_in 结构定义在这里*/
#include
#include
#include
#include
#define PORT 3049 /*服务器端口监听号*/
void doclient(FILE *fp,int sockfd);
main(int argc,char*argv[])
{
int sockfd,n;
struct hostent *he;/*???????*/
struct sockaddr_in server_addr;/*connector's address*/
if (argc!=2)
{
fprintf(stderr,"usage:client hostname \n");
exit(1);
}
printf("gethostbyname begin\n");
if ((he =(struct hostent*)gethostbyname(argv[1]))==NULL)
{
herror("gethostbyname");
exit(1);
}
printf("gethostbyname end\n");
/*建立与服务器的连接*/
if ((sockfd = socket(AF_INET,SOCK_STREAM,0))==-1)
{
perror("socket");
exit(1);
}
bzero(&server_addr,sizeof(server_addr));
server_addr.sin_family=AF_INET;
server_addr.sin_port=htons(PORT);
//server_addr.sin_addr=((struct in_addr*)he->h_addr);
inet_pton(AF_INET,argv[1],&server_addr.sin_addr);
if (connect(sockfd,(struct sockaddr*)&server_addr,sizeof(struct sockaddr))==-1)
{
perror("connect");
exit(1);
}
doclient(stdin,sockfd);
return(0);
}
void doclient(FILE *fp,int sockfd)
{
char sendline[2047],recvline[2048];
int n;
/*下面进入处理循环,当接收到文件结束符Ctrl+D时跳出*/
do{
if ((n=read(sockfd,recvline,2047))==0)
{
perror("read");
exit(1);
}
recvline[n]=0;/*给结尾加上0*/
fputs(recvline,stdout);
if (fgets(sendline,2048,fp)!=NULL)
{
write(sockfd,sendline,strlen(sendline));
}
else
{
break;
}
}while(1);
}
————————————————————————————-
/* server.c */
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define MYPORT 3049 /*服务器端口监听号*/
#define BACKLOG 10 /*最大同时连接请求数*/
void sig_chld();
void echoclient(int);
int main()
{
int listenfd,new_fd;
struct sockaddr_in my_addr;
struct sockaddr_in their_addr;
int sin_size;
/*建立监听套接口*/
if ((listenfd=socket(AF_INET,SOCK_STREAM,0))==-1)
{
perror("socket");
exit(1);
}
bzero(&(my_addr),sizeof(my_addr));
/*void bzero(void *s, int n);置字节字符串s的前n个字节为零*/
my_addr.sin_family=AF_INET;/*internet域的地址族*/
my_addr.sin_port=htons(MYPORT);/*hostshort 转换成网络字节顺序 */
my_addr.sin_addr.s_addr=INADDR_ANY;
/*通配ip地址,告诉系统选择本地机的地址*/
if (bind(listenfd,(struct sockaddr*)&my_addr,sizeof(struct sockaddr))==-1)
{
perror("blind");
exit(1);
}
if (listen(listenfd,BACKLOG)==-1)
{
perror("listen");
exit(1);
}
signal(SIGCHLD,sig_chld);/*处理子进程终止信号,避免僵尸进程*/
/*void (*signal(int,void(*)(int))(int);*/
for(;;)/* accept loop,循环处理listen中的客户请求队列*/
{
sin_size = sizeof(struct sockaddr_in);
if ((new_fd=accept(listenfd,(struct sockaddr*)&their_addr,&sin_size))==-1)
{
if (errno==EINTR)/*EINTR:当睡眠时接收到其他信号*/
{
continue;/*accept 调用可能被信号打断*/
}
perror("accept");
continue;
}
printf("server:got connection from%s\n",inet_ntoa(their_addr.sin_addr));
/*char * inet_ntoa( struct in_addr in); 将网络地址转换成“.”点隔的字符串格式*/
if (!fork())/* fork出子进程处理客户请求*/
{
close(listenfd);
if (send(new_fd,"Hello world!",13,0)==-1)
{
perror("send");
}
echoclient(new_fd);/*调用函数,信息返回给客户*/
exit(0);/*0时正常退出,1时因错误退出*/
}
close(new_fd);
/*父进程关闭刚才的套接口,并继续处理其他的客户请求*/
}
}
void sig_chld()/*SIGHLD 信号捕捉函数*/
{
pid_t pid;
/*:typedef short pid_t;表示的是内核中的进程表的索引 */
int stat;
while((pid=waitpid(-1,&stat,WNOHANG))>0)
/*处理已经结束的子进程,避免僵尸进程*/
/*
pid_t waitpid(pid_t pid, int *statloc, int options);
正常情况下返回pid,
或者0(waitpid在非block模式下才有可能返回),-1代表错误
WNOHANG:如果还没有退出,不block,返回0;
statloc参数保存了退出进程的状态*/
printf("chile %d terminated\n",pid);/*打印“进程终止”*/
return;
}
void echoclient(int sockfd)
{
int n;
char buf[2048];
for(;;)
{
if ((n=read(sockfd,buf,sizeof(buf)))<=0)
{
break;/*对方关闭连接时,跳出循环*/
}
write(sockfd,buf,n);
/*把接收自客户的数据,原本不动的发送给客户*/
}
close(sockfd);
}
————————————————————————————-
现在让我们来编译这两个程序:
root@linuxaid#gcc -o server server.c
root@linuxaid#gcc -o client client.c
然后在一台计算机上先运行服务器程序,再在另一个终端上运行客户端就会看到结果。
————————————————————————————-
建立一个TCP连接需要三次握手,而断开一个TCP则需要四个分节。当某个应用进程调用close(主动端)后(可以是服务器端,也可以是客户端),这一端的TCP发送一个FIN,表示数据发送完毕;另一端(被动端)发送一个确认,当被动端待处理的应用进程都处理完毕后,发送一个FIN到主动端,并关闭套接口,主动端接收到这个FIN后再发送一个确认,到此为止这个TCP连接被断开。
2、UDP套接口
————————————————————————————-
/* server.c */
#include <sys/types.h>
#include <sys/socket.h>
#include <string.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#define MAXLINE 80
#define SERV_PORT 8888
void do_echo(int sockfd, struct sockaddr *pcliaddr, socklen_t clilen)
{
int n;
socklen_t len;
char mesg[MAXLINE];
for(;;)
{
len = clilen;
/* waiting for receive data */
n = recvfrom(sockfd, mesg, MAXLINE, 0, pcliaddr, &len);
/* sent data back to client */
sendto(sockfd, mesg, n, 0, pcliaddr, len);
}
}
int main(void)
{
int sockfd;
struct sockaddr_in servaddr, cliaddr;
sockfd = socket(AF_INET, SOCK_DGRAM, 0); /* create a socket */
/* init servaddr */
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(SERV_PORT);
/* bind address and port to socket */
if(bind(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr)) == -1)
{
perror("bind error");
exit(1);
}
do_echo(sockfd, (struct sockaddr *)&cliaddr, sizeof(cliaddr));
return 0;
}
————————————————————————————-
————————————————————————————-
/* client.c */
#include <sys/types.h>
#include <sys/socket.h>
#include <string.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <unistd.h>
#define MAXLINE 80
#define SERV_PORT 8888
void do_cli(FILE *fp, int sockfd, struct sockaddr *pservaddr, socklen_t servlen)
{
int n;
char sendline[MAXLINE], recvline[MAXLINE + 1];
/* connect to server */
if(connect(sockfd, (struct sockaddr *)pservaddr, servlen) == -1)
{
perror("connect error");
exit(1);
}
while(fgets(sendline, MAXLINE, fp) != NULL)
{
/* read a line and send to server */
write(sockfd, sendline, strlen(sendline));
/* receive data from server */
n = read(sockfd, recvline, MAXLINE);
if(n == -1)
{
perror("read error");
exit(1);
}
recvline[n] = 0; /* terminate string */
fputs(recvline, stdout);
}
}
int main(int argc, char **argv)
{
int sockfd;
struct sockaddr_in srvaddr;
/* check args */
if(argc != 2)
{
printf("usage: udpclient <IPaddress>\n");
exit(1);
}
/* init servaddr */
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(SERV_PORT);
if(inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0)
{
printf("[%s] is not a valid IPaddress\n", argv[1]);
exit(1);
}
sockfd = socket(AF_INET, SOCK_DGRAM, 0);
do_cli(stdin, sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
return 0;
}
————————————————————————————-
1、编译例子程序
使用如下命令来编译例子程序:
gcc -Wall -o udpserv udpserv.c
gcc -Wall -o udpclient udpclient.c
编译完成生成了udpserv和udpclient两个可执行程序。
2、运行UDP Server程序
执行./udpserv &命令来启动服务程序。我们可以使用netstat -ln命令来观察服务程序绑定的IP地址和端口,部分输出信息如下:
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:32768 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6000 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
udp 0 0 0.0.0.0:32768 0.0.0.0:*
udp 0 0 0.0.0.0:8888 0.0.0.0:*
udp 0 0 0.0.0.0:111 0.0.0.0:*
udp 0 0 0.0.0.0:882 0.0.0.0:*
可以看到udp处有“0.0.0.0:8888”的内容,说明服务程序已经正常运行,可以接收主机上任何IP地址且端口为8888的数据。
如果这时再执行./udpserv &命令,就会看到如下信息:
bind error: Address already in use
说明已经有一个服务程序在运行了。
3、运行UDP Client程序
执行./udpclient 127.0.0.1命令来启动客户程序,使用127.0.0.1来连接服务程序,执行效果如下:
Hello, World!
Hello, World!
this is a test
this is a test
^d
输入的数据都正确从服务程序返回了,按ctrl+d可以结束输入,退出程序。
如果服务程序没有启动,而执行客户程序,就会看到如下信息:
$ ./udpclient 127.0.0.1
test
read error: Connection refused
说明指定的IP地址和端口没有服务程序绑定,客户程序就退出了。这就是使用connect()的好处,注意,这里错误信息是在向服务程序发送数据后收到的,而不是在调用connect()时。如果你使用tcpdump程序来抓包,会发现收到的是ICMP的错误信息。
CPU卡基础知识及认证方法
Java 字符串格式转换
/**
* 通信格式转换
*
* Java和一些windows编程语言如c、c++、delphi所写的网络程序进行通讯时,需要进行相应的转换
* 高、低字节之间的转换
* windows的字节序为低字节开头
* linux,unix的字节序为高字节开头
* java则无论平台变化,都是高字节开头
*/
public class FormatTransfer {
/**
* 将int转为低字节在前,高字节在后的byte数组
* @param n int
* @return byte[]
*/
public static byte[] toLH(int n) {
byte[] b = new byte[4];
b[0] = (byte) (n & 0xff);
b[1] = (byte) (n >> 8 & 0xff);
b[2] = (byte) (n >> 16 & 0xff);
b[3] = (byte) (n >> 24 & 0xff);
return b;
}
/**
* 将int转为高字节在前,低字节在后的byte数组
* @param n int
* @return byte[]
*/
public static byte[] toHH(int n) {
byte[] b = new byte[4];
b[3] = (byte) (n & 0xff);
b[2] = (byte) (n >> 8 & 0xff);
b[1] = (byte) (n >> 16 & 0xff);
b[0] = (byte) (n >> 24 & 0xff);
return b;
}
/**
* 将short转为低字节在前,高字节在后的byte数组
* @param n short
* @return byte[]
*/
public static byte[] toLH(short n) {
byte[] b = new byte[2];
b[0] = (byte) (n & 0xff);
b[1] = (byte) (n >> 8 & 0xff);
return b;
}
/**
* 将short转为高字节在前,低字节在后的byte数组
* @param n short
* @return byte[]
*/
public static byte[] toHH(short n) {
byte[] b = new byte[2];
b[1] = (byte) (n & 0xff);
b[0] = (byte) (n >> 8 & 0xff);
return b;
}
/**
* 将将int转为高字节在前,低字节在后的byte数组
public static byte[] toHH(int number) {
int temp = number;
byte[] b = new byte[4];
for (int i = b.length - 1; i > -1; i--) {
b = new Integer(temp & 0xff).byteValue();
temp = temp >> 8;
}
return b;
}
public static byte[] IntToByteArray(int i) {
byte[] abyte0 = new byte[4];
abyte0[3] = (byte) (0xff & i);
abyte0[2] = (byte) ((0xff00 & i) >> 8);
abyte0[1] = (byte) ((0xff0000 & i) >> 16);
abyte0[0] = (byte) ((0xff000000 & i) >> 24);
return abyte0;
}
*/
/**
* 将float转为低字节在前,高字节在后的byte数组
*/
public static byte[] toLH(float f) {
return toLH(Float.floatToRawIntBits(f));
}
/**
* 将float转为高字节在前,低字节在后的byte数组
*/
public static byte[] toHH(float f) {
return toHH(Float.floatToRawIntBits(f));
}
/**
* 将String转为byte数组
*/
public static byte[] stringToBytes(String s, int length) {
while (s.getBytes().length < length) {
s += " ";
}
return s.getBytes();
}
/**
* 将字节数组转换为String
* @param b byte[]
* @return String
*/
public static String bytesToString(byte[] b) {
StringBuffer result = new StringBuffer("");
int length = b.length;
for (int i=0; i<length; i++) {
result.append((char)(b & 0xff));
}
return result.toString();
}
/**
* 将字符串转换为byte数组
* @param s String
* @return byte[]
*/
public static byte[] stringToBytes(String s) {
return s.getBytes();
}
/**
* 将高字节数组转换为int
* @param b byte[]
* @return int
*/
public static int hBytesToInt(byte[] b) {
int s = 0;
for (int i = 0; i < 3; i++) {
if (b >= 0) {
s = s + b;
} else {
s = s + 256 + b;
}
s = s * 256;
}
if (b[3] >= 0) {
s = s + b[3];
} else {
s = s + 256 + b[3];
}
return s;
}
/**
* 将低字节数组转换为int
* @param b byte[]
* @return int
*/
public static int lBytesToInt(byte[] b) {
int s = 0;
for (int i = 0; i < 3; i++) {
if (b[3-i] >= 0) {
s = s + b[3-i];
} else {
s = s + 256 + b[3-i];
}
s = s * 256;
}
if (b[0] >= 0) {
s = s + b[0];
} else {
s = s + 256 + b[0];
}
return s;
}
/**
* 高字节数组到short的转换
* @param b byte[]
* @return short
*/
public static short hBytesToShort(byte[] b) {
int s = 0;
if (b[0] >= 0) {
s = s + b[0];
} else {
s = s + 256 + b[0];
}
s = s * 256;
if (b[1] >= 0) {
s = s + b[1];
} else {
s = s + 256 + b[1];
}
short result = (short)s;
return result;
}
/**
* 低字节数组到short的转换
* @param b byte[]
* @return short
*/
public static short lBytesToShort(byte[] b) {
int s = 0;
if (b[1] >= 0) {
s = s + b[1];
} else {
s = s + 256 + b[1];
}
s = s * 256;
if (b[0] >= 0) {
s = s + b[0];
} else {
s = s + 256 + b[0];
}
short result = (short)s;
return result;
}
/**
* 高字节数组转换为float
* @param b byte[]
* @return float
*/
public static float hBytesToFloat(byte[] b) {
int i = 0;
Float F = new Float(0.0);
i = ((((b[0]&0xff)<<8 | (b[1]&0xff))<<8) | (b[2]&0xff))<<8 | (b[3]&0xff);
return F.intBitsToFloat(i);
}
/**
* 低字节数组转换为float
* @param b byte[]
* @return float
*/
public static float lBytesToFloat(byte[] b) {
int i = 0;
Float F = new Float(0.0);
i = ((((b[3]&0xff)<<8 | (b[2]&0xff))<<8) | (b[1]&0xff))<<8 | (b[0]&0xff);
return F.intBitsToFloat(i);
}
/**
* 将byte数组中的元素倒序排列
*/
public static byte[] bytesReverseOrder(byte[] b) {
int length = b.length;
byte[] result = new byte[length];
for(int i=0; i<length; i++) {
result[length-i-1] = b;
}
return result;
}
/**
* 打印byte数组
*/
public static void printBytes(byte[] bb) {
int length = bb.length;
for (int i=0; i<length; i++) {
System.out.print(bb + " ");
}
System.out.println("");
}
public static void logBytes(byte[] bb) {
int length = bb.length;
String out = "";
for (int i=0; i<length; i++) {
out = out + bb + " ";
}
}
/**
* 将int类型的值转换为字节序颠倒过来对应的int值
* @param i int
* @return int
*/
public static int reverseInt(int i) {
int result = FormatTransfer.hBytesToInt(FormatTransfer.toLH(i));
return result;
}
/**
* 将short类型的值转换为字节序颠倒过来对应的short值
* @param s short
* @return short
*/
public static short reverseShort(short s) {
short result = FormatTransfer.hBytesToShort(FormatTransfer.toLH(s));
return result;
}
/**
* 将float类型的值转换为字节序颠倒过来对应的float值
* @param f float
* @return float
*/
public static float reverseFloat(float f) {
float result = FormatTransfer.hBytesToFloat(FormatTransfer.toLH(f));
return result;
}
}
详解UML中的6大关系(关联、依赖、聚合、组合、泛化、实现)
大话设计模式上的一个图,我用EA画出来的:

UML中的6大关系相关英文及音标:
|
依赖关系 |
dependency |
[di'pendənsi] |
|
关联关系 |
association |
[ə,səuʃi'eiʃən] |
|
聚合关系 |
aggregation |
[,ægrɪˈgeɪʃən] |
|
组合关系 |
composition |
[,kɔmpə'ziʃən] |
|
实现 |
realization |
[,ri:əlɪ'zeɪʃən] |
|
泛化 |
generalization |
[,dʒenərəlɪ'zeɪʃən] |
UML中的6大关系简单解释:
- 关联:连接模型元素及链接实例,用一条实线来表示;
- 依赖:表示一个元素以某种方式依赖于另一个元素,用一条虚线加箭头来表示;
- 聚合:表示整体与部分的关系,用一条实线加空心菱形来表示;
- 组成:表示整体与部分的有一关系,用一条实线加实心菱形来表示;
- 泛化(继承):表示一般与特殊的关系,用一条实线加空心箭头来表示;
- 实现:表示类与接口的关系,用一条虚线加空心箭头来表示;
注意:泛化关系和实现关系又统称为一般关系;
总之:一般关系表现为继承或实现(is a),关联关系、聚合关系、合成/组合关系表现为成员变量(has a),依赖关系表现为函数中的参数(use a);
转自:http://www.cnblogs.com/ForEverKissing/archive/2007/12/13/993818.html
UML中的6大关系详细说明:
1、关联关系:
含义:类与类之间的连结,关联关系使一个类知道另外一个类的属性和方法;通常含有“知道”,“了解”的含义
体现:在C#中,关联关系是通过成员变量来实现的;
方向:双向或单向;
图示:实线 + 箭头;箭头指向被关联的类;
举例:“渔民”需要知道“天气”情况才能够出海
//公司关联雇员
public class Company
{
private Employee employee;
public Employee GetEmployee()
{
return employee;
}
public void SetEmployee(Employee employee)
{
this.employee = employee;
}
//公司运作
public void Run()
{
employee.StartWorking();
}
}
//A关联B
class A
{
B b = new B();
}
class B
{
}
2、依赖关系:
含义:是类与类之间的连接,表示一个类依赖于另外一个类的定义;依赖关系仅仅描述了类与类之间的一种使用与被使用的关系;
体现:在C#中体现为局部变量、方法/函数的参数或者是对静态方法的调用;
方向:单向;
图示:虚线 + 箭头;
举例:人依赖于水和空气;汽车依赖汽油
//人划船,人依赖于船
public class Person
{
//划船
public void Oarage(Boat boat)
{
boat.Oarage();
}
}
//A依赖于B
class A
{
public void Function(B b)
{ }
}
class B
{
}
3、聚合关系:
含义:是关联关系的一种,是一种强关联关系;聚合关系是整体和个体/部分之间的关系;关联关系的两个类处于同一个层次上,而聚合关系的两个类处于不同的层次上,一个是整体,一个是个体/部分;在聚合关系中,代表个体/部分的对象有可能会被多个代表整体的对象所共享;
体现:C++中,聚合关系通过将被聚合者的(数组)指针作为内部成员来实现的;
方向:单向;
图示:空心菱形 + 实线 + 箭头;箭头指向被聚合的类,也就是说,箭头指向个体/部分;
举例:鸭群与鸭子具有聚合关系;汽车由引擎、轮胎以及其它零件组成,因为汽车坏掉了,没有坏掉的引擎,轮胎和其他零件还可以继续使用。
4、组合关系:
含义:它也是关联关系的一种,但它是比聚合关系更强的关系.组合关系要求聚合关系中代表整体的对象要负责代表个体/部分的对象的整个生命周期;组合关系不能共享;在组合关系中,如果代表整体的对象被销毁或破坏,那么代表个体/部分的对象也一定会被销毁或破坏,而聚在合关系中,代表个体/部分的对象则有可能被多个代表整体的对象所共享,而不一定会随着某个代表整体的对象被销毁或破坏而被销毁或破坏;
体现:在C#中,组合关系是通过成员变量来实现的;
方向:单向;
图示:实心菱形 + 实线 + 箭头;箭头指向代表个体/部分的对象,也就是被组合的类的对象;
举例:一个人由头、四肢、等各种器官组成,因为人与这些器官具有相同的生命周期,人死了,这些器官也挂了;
5、泛化关系:
含义:它表示一个更泛化的元素和一个更具体的元素之间的关系;也就是通常所说的类的继承关系;
体现:在C#中,泛化关系通过类的继承来实现的;
方向:单向;子类继承父类;
图示:空心箭头 + 实线;箭头指向父类;
举例:动物下面可以分为哺乳动物,脊椎动物,爬行动物等
6、实现关系:
含义:它指定了两个实体之间的一份合同;即:一个实体定义一份合同,另外一个实体则保证履行该合同;
体现:在C#中,实现关系通过类实现接口来实现的,即:一个类实现某个接口;
方向:单向;子类实现接口;
图示:空心箭头 + 虚线;箭头指接口向接口;
举例:唐老鸭(对象)会说话(接口),因为一般鸭子不会说话,所以不会将说话这个方法给一般的鸭子带上;超人(对象)会飞(接口)
转自:http://www.cnblogs.com/aicro/archive/2010/08/23/1806584.html
UML中的6大关系参考:
你是我的玫瑰-类关系阐微
http://www.cnblogs.com/zjzkiss/archive/2007/05/06/736725.html
UML中关联、依赖、聚集等关系的异同
http://www.cnblogs.com/ForEverKissing/archive/2007/12/13/993818.html
UML 类与类之间的关系
http://yanwenhan.javaeye.com/blog/149450
类间的关系
http://www.cnblogs.com/floodpeak/archive/2008/02/27/1083533.html
UML解惑:图说UML中的六大关系
http://developer.51cto.com/art/201004/194204.htm
大话设计模式
详解公钥、私钥、数字证书的概念
加密和认证
首先我们需要区分加密和认证这两个基本概念。
加密是将数据资料加密,使得非法用户即使取得加密过的资料,也无法获取正确的资料内容,所以数据加密可以保护数据,防止监听攻击。其重点在于数据的安全性。身份认证是用来判断某个身份的真实性,确认身份后,系统才可以依不同的身份给予不同的权限。其重点在于用户的真实性。两者的侧重点是不同的。
公钥和私钥
公钥和私钥就是俗称的不对称加密方式,是从以前的对称加密(使用用户名与密码)方式的提高。
在现代密码体制中加密和解密是采用不同的密钥(公开密钥),也就是非对称密钥密码系统,每个通信方均需要两个密钥,即公钥和私钥,这两把密钥可以互为加解密。公钥是公开的,不需要保密,而私钥是由个人自己持有,并且必须妥善保管和注意保密。
公钥私钥的原则:
- 一个公钥对应一个私钥。
- 密钥对中,让大家都知道的是公钥,不告诉大家,只有自己知道的,是私钥。
- 如果用其中一个密钥加密数据,则只有对应的那个密钥才可以解密。
- 如果用其中一个密钥可以进行解密数据,则该数据必然是对应的那个密钥进行的加密。
用电子邮件的方式说明一下原理。
使用公钥与私钥的目的就是实现安全的电子邮件,必须实现如下目的:
1. 我发送给你的内容必须加密,在邮件的传输过程中不能被别人看到。
2. 必须保证是我发送的邮件,不是别人冒充我的。
要达到这样的目标必须发送邮件的两人都有公钥和私钥。
公钥,就是给大家用的,你可以通过电子邮件发布,可以通过网站让别人下载,公钥其实是用来加密/验章用的。私钥,就是自己的,必须非常小心保存,最好加上 密码,私钥是用来解密/签章,首先就Key的所有权来说,私钥只有个人拥有。公钥与私钥的作用是:用公钥加密的内容只能用私钥解密,用私钥加密的内容只能 用公钥解密。
比如说,我要给你发送一个加密的邮件。首先,我必须拥有你的公钥,你也必须拥有我的公钥。
首先,我用你的公钥给这个邮件加密,这样就保证这个邮件不被别人看到,而且保证这个邮件在传送过程中没有被修改。你收到邮件后,用你的私钥就可以解密,就能看到内容。
其次我用我的私钥给这个邮件加密,发送到你手里后,你可以用我的公钥解密。因为私钥只有我手里有,这样就保证了这个邮件是我发送的。
非对称密钥密码的主要应用就是公钥加密和公钥认证,而公钥加密的过程和公钥认证的过程是不一样的,下面我就详细讲解一下两者的区别。
基于公开密钥的加密过程
比如有两个用户Alice和Bob,Alice想把一段明文通过双钥加密的技术发送给Bob,Bob有一对公钥和私钥,那么加密解密的过程如下:
- Bob将他的公开密钥传送给Alice。
- Alice用Bob的公开密钥加密她的消息,然后传送给Bob。
- Bob用他的私人密钥解密Alice的消息。
Alice使用Bob的公钥进行加密,Bob用自己的私钥进行解密。
基于公开密钥的认证过程
身份认证和加密就不同了,主要用户鉴别用户的真伪。这里我们只要能够鉴别一个用户的私钥是正确的,就可以鉴别这个用户的真伪。
还是Alice和Bob这两个用户,Alice想让Bob知道自己是真实的Alice,而不是假冒的,因此Alice只要使用公钥密码学对文件签名发送给Bob,Bob使用Alice的公钥对文件进行解密,如果可以解密成功,则证明Alice的私钥是正确的,因而就完成了对Alice的身份鉴别。整个身份认证的过程如下:
- Alice用她的私人密钥对文件加密,从而对文件签名。
- Alice将签名的文件传送给Bob。
- Bob用Alice的公钥解密文件,从而验证签名。
Alice使用自己的私钥加密,Bob用Alice的公钥进行解密。
根证书
根证书是CA认证中心给自己颁发的证书,是信任链的起始点。安装根证书意味着对这个CA认证中心的信任。
总结
根据非对称密码学的原理,每个证书持有人都有一对公钥和私钥,这两把密钥可以互为加解密。公钥是公开的,不需要保密,而私钥是由证书持人自己持有,并且必须妥善保管和注意保密。
数字证书则是由证书认证机构(CA)对证书申请者真实身份验证之后,用CA的根证书对申请人的一些基本信息以及申请人的公钥进行签名(相当于加盖发证书机构的公章)后形成的一个数字文件。CA完成签发证书后,会将证书发布在CA的证书库(目录服务器)中,任何人都可以查询和下载,因此数字证书和公钥一样是公开的。
可以这样说,数字证书就是经过CA认证过的公钥,而私钥一般情况都是由证书持有者在自己本地生成的,由证书持有者自己负责保管。具体使用时,签名操作是发送方用私钥进行签名,接受方用发送方证书来验证签名;加密操作则是用接受方的证书进行加密,接受方用自己的私钥进行解密。
SQLite3 使用教学
OS X自从10.4后把SQLite这套相当出名的数据库软件,放进了作业系统工具集里。OS X包装的是第三版的SQLite,又称SQLite3。这套软件有几个特色:
-
软件属于公共财(public domain),SQLite可说是某种「美德软件」(virtueware),作者本人放弃着作权,而给使用SQLite的人以下的「祝福」(blessing):
- May you do good and not evil. 愿你行善莫行恶
- May you find forgiveness for yourself and forgive others. 愿你原谅自己宽恕他人
- May you share freely, never taking more than you give. 愿你宽心与人分享,所取不多于你所施予
- 支援大多数的SQL指令(下面会简单介绍)。
- 一个档案就是一个数据库。不需要安装数据库服务器软件。
- 完整的Unicode支援(因此没有跨语系的问题)。
- 速度很快。
目前在OS X 10.4里,SQLite是以/usr/bin/sqlite3的形式包装,也就说这是一个命令列工具,必须先从终端机(Terminal.app或其他程序)进入shell之后才能使用。网络上有一些息协助使用SQLite的视觉化工具,但似乎都没有像CocoaMySQL(配合MySQL数据库使用)那般好用。或许随时有惊喜也未可知,以下仅介绍命令列的操作方式。
SQLite顾名思议是以SQL为基础的数据库软件,SQL是一套强大的数据库语言,主要概念是由「数据库」、「资料表」(table)、「查询指令」(queries)等单元组成的「关联性数据库」(进一步的概念可参考网络上各种关于SQL及关联性数据库的文件)。因为SQL的查询功能强大,语法一致而入门容易,因此成为现今主流数据库的标准语言(微软、Oracle等大厂的数据库软件都提供SQL语法的查询及操作)。
以下我们就建立数据库、建立资料表及索引、新增资料、查询资料、更改资料、移除资料、sqlite3命令列选项等几个项目做简单的介绍。
目录
|
建立数据库档案
用sqlite3建立数据库的方法很简单,只要在shell下键入(以下$符号为shell提示号,请勿键入):
$ sqlite3 foo.db
如果目录下没有foo.db,sqlite3就会建立这个数据库。sqlite3并没有强制数据库档名要怎么取,因此如果你喜欢,也可以取个例如foo.icannameitwhateverilike的档名。
在sqlite3提示列下操作
进入了sqlite3之后,会看到以下文字:
SQLite version 3.1.3
Enter ".help" for instructions
sqlite>
这时如果使用.help可以取得求助,.quit则是离开(请注意:不是quit)
SQL的指令格式
所以的SQL指令都是以分号(;)结尾的。如果遇到两个减号(--)则代表注解,sqlite3会略过去。
建立资料表
假设我们要建一个名叫film的资料表,只要键入以下指令就可以了:
create table film(title, length, year, starring);
这样我们就建立了一个名叫film的资料表,里面有name、length、year、starring四个字段。
这个create table指令的语法为:
create table table_name(field1, field2, field3, ...);
table_name是资料表的名称,fieldx则是字段的名字。sqlite3与许多SQL数据库软件不同的是,它不在乎字段属于哪一种资料型态:sqlite3的字段可以储存任何东西:文字、数字、大量文字(blub),它会在适时自动转换。
建立索引
如果资料表有相当多的资料,我们便会建立索引来加快速度。好比说:
create index film_title_index on film(title);
意思是针对film资料表的name字段,建立一个名叫film_name_index的索引。这个指令的语法为
create index index_name on table_name(field_to_be_indexed);
一旦建立了索引,sqlite3会在针对该字段作查询时,自动使用该索引。这一切的操作都是在幕后自动发生的,无须使用者特别指令。
加入一笔资料
接下来我们要加入资料了,加入的方法为使用insert into指令,语法为:
insert into table_name values(data1, data2, data3, ...);
例如我们可以加入
insert into film values ('Silence of the Lambs, The', 118, 1991, 'Jodie Foster');
insert into film values ('Contact', 153, 1997, 'Jodie Foster');
insert into film values ('Crouching Tiger, Hidden Dragon', 120, 2000, 'Yun-Fat Chow');
insert into film values ('Hours, The', 114, 2002, 'Nicole Kidman');
如果该字段没有资料,我们可以填NULL。
查询资料
讲到这里,我们终于要开始介绍SQL最强大的select指令了。我们首先简单介绍select的基本句型:
select columns from table_name where expression;
最常见的用法,当然是倒出所有数据库的内容:
select * from film;
如果资料太多了,我们或许会想限制笔数:
select * from film limit 10;
或是照着电影年份来排列:
select * from film order by year limit 10;
或是年份比较近的电影先列出来:
select * from film order by year desc limit 10;
或是我们只想看电影名称跟年份:
select title, year from film order by year desc limit 10;
查所有茱蒂佛斯特演过的电影:
select * from film where starring='Jodie Foster';
查所有演员名字开头叫茱蒂的电影('%' 符号便是 SQL 的万用字符):
select * from film where starring like 'Jodie%';
查所有演员名字以茱蒂开头、年份晚于1985年、年份晚的优先列出、最多十笔,只列出电影名称和年份:
select title, year from film where starring like 'Jodie%' and year >= 1985 order by year desc limit 10;
有时候我们只想知道数据库一共有多少笔资料:
select count(*) from film;
有时候我们只想知道1985年以后的电影有几部:
select count(*) from film where year >= 1985;
(进一步的各种组合,要去看SQL专书,不过你大概已经知道SQL为什么这么流行了:这种语言允许你将各种查询条件组合在一起──而我们还没提到「跨数据库的联合查询」呢!)
如何更改或删除资料
了解select的用法非常重要,因为要在sqlite更改或删除一笔资料,也是靠同样的语法。
例如有一笔资料的名字打错了:
update film set starring='Jodie Foster' where starring='Jodee Foster';
就会把主角字段里,被打成'Jodee Foster'的那笔(或多笔)资料,改回成Jodie Foster。
delete from film where year < 1970;
就会删除所有年代早于1970年(不含)的电影了。
其他sqlite的特别用法
sqlite可以在shell底下直接执行命令:
sqlite3 film.db "select * from film;"
输出 HTML 表格:
sqlite3 -html film.db "select * from film;"
将数据库「倒出来」:
sqlite3 film.db ".dump" > output.sql
利用输出的资料,建立一个一模一样的数据库(加上以上指令,就是标准的SQL数据库备份了):
sqlite3 film.db < output.sql
在大量插入资料时,你可能会需要先打这个指令:
begin;
插入完资料后要记得打这个指令,资料才会写进数据库中:
commit;
小结
以上我们介绍了SQLite这套数据库系统的用法。事实上OS X也有诸于SQLiteManagerX这类的图形接口程序,可以便利数据库的操作。不过万变不离其宗,了解SQL指令操作,SQLite与其各家变种就很容易上手了。
至于为什么要写这篇教学呢?除了因为OS X Tiger大量使用SQLite之外(例如:Safari的RSS reader,就是把文章存在SQLite数据库里!你可以开开看~/Library/Syndication/Database3这个档案,看看里面有什么料),OpenVanilla从0.7.2开始,也引进了以SQLite为基础的词汇管理工具,以及全字库的注音输入法。因为使用SQLite,这两个模块不管数据库内有多少笔资料,都可以做到「瞬间启动」以及相当快速的查询回应。
将一套方便好用的数据库软件包进OS X中,当然也算是Apple相当相当聪明的选择。再勤劳一点的朋友也许已经开始想拿SQLite来记录各种东西(像我们其中就有一人写了个程序,自动记录电池状态,写进SQLite数据库中再做统计......)了。想像空间可说相当宽广。
目前支援SQLite的程序语言,你能想到的大概都有了。这套数据库2005年还赢得了美国O'Reilly Open Source Conference的最佳开放源代码软件奖,奖评是「有什么东西能让Perl, Python, PHP, Ruby语言团结一致地支援的?就是SQLite」。由此可见SQLite的地位了。而SQLite程序非常小,更是少数打 "gcc -o sqlite3 *",不需任何特殊设定就能跨平台编译的程序。小而省,小而美,SQLite连网站都不多赘言,直指SQL语法精要及API使用方法,原作者大概也可以算是某种程序设计之道(Tao of Programming)里所说的至人了。
Enjoy /usr/bin/sqlite3 in your OS X Tiger. :)
细说业务逻辑
前言
记得几个月前,在一次北京博客园俱乐部的活动上,最后一个环节是话题自由讨论。就是提几个话题,然后大家各自加入感兴趣的话题小组,进行自由讨论。当时金 色海洋同学提出了一个话题——“什么是业务逻辑”。当时我和大家讨论ASP.NET MVC的相关话题去了,就没能加入“业务逻辑”组的讨论,比较遗憾。
其实,一段时间内,我脑子里对“业务逻辑”的概念也是非常模糊的。但在不断地阅读、思考和实践过程中,这个概念及其相关的内容才在我脑子里渐渐清晰。我 想,很多朋友也许也对这个概念不是很了解,所以愿意结合既有资料和自己的思考,总结一篇关于业务逻辑的概述性文章,一则与朋友们分享探讨,二则也是为自己 对业务逻辑的学习做一个总结和提升。因为我还不敢说对业务逻辑内涵及外延理解的非常充分,所以文中如有不当之处,还请各位不用客气,尽管批评就好!
内容提要
===================前篇=====================
前言
内容提要
1、我把业务逻辑丢了!——找回丢失的业务逻辑
2、细说业务逻辑
2.1、业务逻辑到底是什么
2.2、业务逻辑的组成结构
2.2.1、领域实体(Domain Entity)
2.2.2、业务规则(Business Rules)
2.2.3、完整性约束(Validation)
2.2.4、业务流程及工作流(Business Processes and Workflows)
2.3、业务逻辑层职责相关争议
2.3.1、争议一:数据的格式化
2.3.2、争议二:数据合法性及完整性验证
2.3.3、争议三:CRUD
2.3.4、争议四:存储过程
===================后篇=====================
3、业务逻辑的架构模式及实现
3.1、Transcaton Script
3.1.1、概述
3.1.2、分析
3.2、Table Module
3.2.1、概述
3.2.2、分析
3.3、Active Record
3.3.1、概述
3.3.2、分析
3.4、Domain Model
3.4.1、概述
3.4.2、分析
3.5、各种架构模式的比较及选择
4、结束语
参考文献
1、我把业务逻辑丢了!——找回丢失的业务逻辑
相信朋友们基本都是软件开发人员。不论身处什么职位,我们的工作都有一个共同的目标——制作软件产品。而所谓的软件产品,一定是在某个领域内去实现某些业务 。如此看来,“业务逻辑”本应和“软件产品”是紧紧绑在一起的,没有业务逻辑,何来软件产品?
但是,我发现一个奇怪的现象,一说业务逻辑,很多人就无法形成清晰地印象。例如,经典的三层架构:表示层、业务逻辑层和数据访问层,一提到表示层或数据访 问层,大家脑子里马上能产生出清晰的概念,但一提到业务逻辑层,就有点模糊了,或者完全不知道其是什么,或者有个模糊的轮廓,但对其具体的职责、结构不是 很清楚。真是奇了怪了!我们天天和业务逻辑打交道,搞不清业务逻辑是什么。
对于这个奇怪的现象,我思前想后,结合自身的教训(我也曾很长时间搞不清业务逻辑),终于弄清楚了其原因——这和我们接触这个概念的途径和认知结构有莫大 关系。
不知道有多少人和我一样,首次接触“业务逻辑”这个概念是从分层架构中的“业务逻辑层”概念开始的,我相信不在少数。事情坏就坏在这里!为了让朋友们直观 看清“业务逻辑”的概念是怎么被我们丢掉的,请大家看一个图,这个图展示了很多人对“业务逻辑”的认知过程。
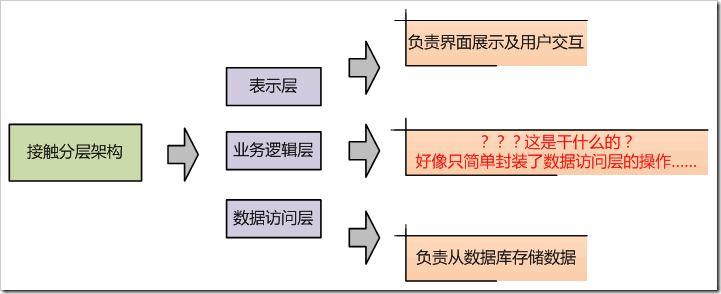
图 1-1、狭义的认知分解过程
如图1-1所示,我们先接触了分层架构,然后对每个层产生了初步的认识。其中,由于表示层和数据访问层的代码职责清晰明确,基本能正确认识。但是,由于我 们接触的分层架构的Demo大多业务极其简单,又基本是CRUD操作集中型的业务。所以,我们脑子中就产生了疑问:这个所谓的业务逻辑层是干什么的?怎么 就简单封装了一下数据访问层的操作?这有存在的必要吗?由于有了这种“先入为主”的误导,使得很多朋友脑中将“业务逻辑”和“业务逻辑层”两个概念混淆 了,始终想不明白这东西到底是什么,做什么用的。再加上很多朋友所看的、所做的系统都是CRUD操作集中型的,就形成了“业务逻辑貌似就是对数据访问操作 的简单封装”这一片面概念。
到底这一概念有没有错呢?其实没错,因为在简单的、CRUD操作集中型软件中,业务逻辑基本就是对数据访问简单的封装。但是,无错不代表全面,这是一种狭 义的业务逻辑理解,而且是狭义中的狭义。为什么这么说呢?因为我们不但是在“业务逻辑层”这么一个狭义范围内去理解业务逻辑,而且还是CRUD集中型操作 这种“非常瘦”的业务逻辑层范围内去理解,所以,可谓是在狭义的基础上的狭义。
当我们把这么一个“狭义中的狭义业务逻辑”与“业务逻辑”等同起来时,误会、迷茫、困惑、不屑就出现了。这就如同,给你一只温顺的哈巴狗,还是病怏怏的、 无精打采的小哈巴狗,而你把这只“病怏怏的小哈巴狗”与“狗”的概念等同起来了。那么你一定就会为有人养狗看家和警察养狗当警犬抓坏人而困惑:这东西这么 弱小,我一脚就踩死了,怎么弄用来看家和抓坏人呢?进而可能会产生“狗狗无用论”,“狗狗废品”等观念。当然,在现实中,很少有人只见过小哈巴狗而没见过 狼狗等其它狗类,所以,故事中的误会对 “狗”一般是不存在的。但在现实中,确实有很多人只见过业务逻辑中的“小哈巴狗”,却没有见过业务逻辑中的“狼狗”、“藏獒”,所以,这种误会在对“业务 逻辑”的理解上广泛存在。
那么,广义的情况究竟是怎么样的?请看下图。
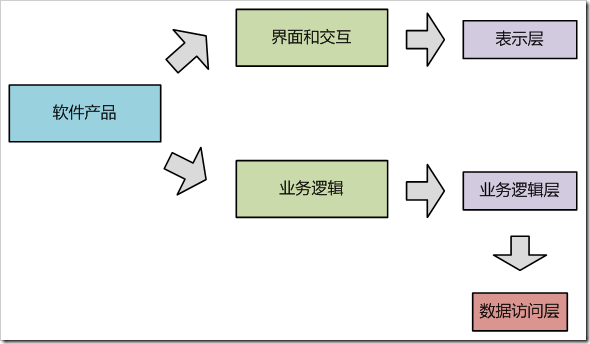
图 1-2、广义的认知分解过程
(注意!凡是不特别说明,下文中所有“数据”一词都指需要持久化的数据,而不包括内存中的临时数据。请各位留心。)
如图1-2所示,广义的认知分解应该是这样的:软件产品都是在某个领域内实现某些特定业务,所以,软件产品天生应该分解为界面交互部分和业务逻辑部分,其中业务逻辑 部分是软件产品的核心,它客观存在于软件产品内部,但是无法对使用者产生直观刺激,因此业务逻辑不能与使用者直接交互。而界面交互部分是业务逻辑与使用者 进行交流的接口,使用者通过界面交互部分,与业务进行交流,从而使得软件产品发挥其作用。
而在具体实现系统时,界面交互部分演化成表示层,业务逻辑部分演化成业务逻辑层。所以,可以认为,数据访问层不是软件产品自然演化的直接产物,之所以出现 数据访问层,是因为某些产品的业务属于“数据操作集中型”业务,为了实现隔离、复用等目的,架构师从业务逻辑中分离出了频繁使用的数据访问业务,形成了单 独的数据访问层。从广义来说,可以认为数据访问隶属于业务逻辑,因为,数据访问操作实际上也是业务逻辑的一部分。
总结一下几个要点:(这几个要中的业务逻辑均指广义业务逻辑)
1)软件产品自然的可分为界面交互部分和业务逻辑部分。
2)从空间结构上看,业务逻辑和数据访问不是并列关系,而是隶属关系——数据访问隶属于业务逻辑。虽然在具体系统实现层面,数据访问层和业务逻辑层是并列 存在,但从概念本质层面上分析,两者是隶属关系。
3)从时间结构上看,应该是先有业务逻辑的概念,才有数据访问的概念。业务逻辑衍生自软件本身,数据访问衍生自业务逻辑。
4)因为业务逻辑是软件产品自然的一部分,所以拥有业务逻辑是软件产品的必要条件(读者可以试着举出一个不包含业务逻辑的软件)。但是一个软件可以没有数 据访问,如“计算器”、“不带存档的小游戏”等。
利用以上论述要点和认知分解,朋友们可以试试在脑中重新构筑狭义和广义“业务逻辑”的概念。看能不能把我们丢掉的业务逻辑概念找回来。关于业务逻辑更多的 细节,将在下文中讨论。
2、细说业务逻辑
2.1、业务逻辑到底是什么
在第一大节里说了那么多,相信各位基本已经形成“业务逻辑”的概念了。如果我在这里再啰嗦什么,我不嫌累各位也要嫌烦了。所以,这里我仅给出两个定义。
广义上的义务逻 辑——软件本身固有的一种品性,自然存在于软件产品内部,是软件具有的在某个业务领域内的逻辑,是软件的核心和灵魂。软件产品除界面和交互外的一切都可看 作是广义业务逻辑。
狭义上的业务逻 辑——等同于分层架构中“业务逻辑层”的职责,是软件中处理与业务相关任务的部分,一般狭义上的业务逻辑不包含数据持久化,而只关注领域内的相关业务。
对于以上两种定义,希望朋友们不要割裂开来看,而 要辩证统一的去看,这样,才能构建一个完整而辩证统一的“业务逻辑”概念。在下文中,将不再明确区分狭义和广义,“业务逻辑”一词将代表两者的辩证统一 体。
2.2、业务逻辑的组成结构
业务逻辑作为一个高层次概念,其内在结构也是非常丰富的,下面我们深入其里,去探寻一下业务逻辑都是由哪些更底层的部分构成的。
2.2.1、领域实体(Domain Entity)
通俗的说,领域实体就是这个领域内有哪些东西。例如,银行业领域内有账户、支票、前台营业员等实体;B2C电子商务领域有商品、订单、交易等实体;魔兽世 界游戏的领域内有角色、种族、道具、魔法等实体;高等代数领域有矩阵、行列式等实体。
领域实体是某个领域内各种对象的抽象,可以用名词表示(可以是具体名词或抽象名词,甚至动名词,只要其具有名词性),构成了整个业务逻辑的骨骼和静态模 型。一般每个领域实体有自己的一些属性和行为。 顺便说一句,领域实体的存在时OOA&D的基础。
在具体的软件系统中,领域实体往往会根据架构的不同有不同的映射存在形式。
其中一种叫做Business Object(BO),即业务对象,某些文献称其为“充血实体类”,这种对象完整抽象了领域内的某个实体,封装了此实体相关属性和行为。在面向对象的设计 和架构中,这种实体类很常见。
另一种叫做Data Transfer Object(DTO),某些文献称其为“贫血实体类”,其特点是仅有属性,不存在行为。这种实体类主要负责整体性传递数据。另外,与BO不同的 是,DTO可以不抽象领域实体的全部属性,而只根据需要抽象一部分。例如,某个“User”实体存在很多属性,但如果某个方法仅需要其联系方式,可以设计 一个DTO,仅有id,email,address,phone等就够了。在面向过程的设计和架构中,这种实体设计比较常见。
2.2.2、业务规则(Business Rules)
业务规则就是某个领域内运作的规则,构成了整个业务逻辑的灵魂和动态模型。业务规则作用于领域实体,领域实体遵从业务规则进行运作。
如:在银行领域内,“转账时从A账户扣除相应款项,在B账户添加相应款项,并从A账户扣除相应手续费,并通过某些途径通知A和B账户的户主”就是一条规 则。需要注意的是,业务规则比较抽象,并不是需求,需求需要具体且无二义性,而业务规则只是抽象的一种描述,例如,通知户主的途径是什么?电子邮件?电 话?短信?并没有具体描述,但在规则中有“通知”这一项,因此不能将业务规则等同于需求。
2.2.3、完整性约束(Validation)
领域实体和业务规则构建了业务逻辑的主体,但在这主体之上,还存在着一个限制,这就是完整性约束。
完整性约束是对业务领域中的数据、规则的强制性规定与约束。这种约束是系统正常运转的保证。
如“账户密码不能为空”,“身份证号必须符合具体格式规定”,“转账流程必须具有原子性,A账户扣钱、B账户存钱、A账户扣除手续费、通知户主四项操作必 须要么都做,要么都不做”,都是完整性约束。
2.2.4、业务流程及工作流(Business Processes and Workflows)
有了上述三项,业务逻辑还不能正常工作,因为还没有“启动器”和“过程托管器”。设想我们有了各种实体类,它们有各自的属性和行为,也有定义好的业务规则 和完整性约束。现在实体类仅仅具有实现业务规则的能力,但它们如何启动并交互协调完成业务规则呢?因此我们需要有东西去触发和协调实体。
业务流程或工作流是启动及托管协调领域实体完成既定规则的过程。例如,“在线订购”是一个业务流程,它包括“用户登录-选择商品-结算-下订单-付款-确 认收货”这一系列流程。各个实体如会员、订单、商品等已经包含了完成在线订购必要的行为,但仍需一个流程,才能真正完成业务。
具体到程序中,业务流程也许通过一个方法来实现,这个方法负责启动并协调各个实体类,完成一个流程。
2.3、业务逻辑层职责及相关争议
2.3.1、数据的格式化
关于数据的格式化应该放在业务层进行还是表示层进行一直存在争议。我个人的意见是这样的:
业务层送给表示层的数据应该具备以下要求。1)返回的数据应该完成了所有必要的业务处理和业务计算。 例如,若返回订单信息让表示层展示,会有个必要的数据——订单总额。这个数据需要首先用各个订单项的单价乘以数量,然后加和。那么,这个数据应该在业务层 完成计算直接返回,总之不应让表示层进行任何业务处理和计算操作。2)一次 性返回所有需要的数据,避免表示层再一个Action里调用多次业务。 打个比方,例如订单中有个“客户姓名”,这个数据不保存在订单表中,而是通过外键关联的,那么,业务层应该将“客户姓名”一并取出返回给表示层。总之,避 免表示层在一个Action里多次调用业务层。3)不携带任何格式信息,仅 仅是结构良好的纯净数据,如DTO形式。 因为,数据如何展示,是表示层的职责,如何在业务层中返回了过多格式信息,就会造成表示层的修改困难。例如,我曾听说过所里承接的一个实际项目,开始是使 用B/S,当时他们的业务层返回的数据全都附带了html代码。后来,客户嫌B/S响应不够迅速(可能是客户公司的网络条件不好),要求改成C/S,当时 全傻眼了,貌似几乎修改了整个业务层。那个项目相当庞大,7个子系统,投入200人开发了1年多,想想修改的难度吧。
2.3.2、数据合法性及完整性验证
一般做系统,都避免不了数据验证。上文曾经提到,完整性约束是业务逻辑的一部分。如此看来,数据验证一般应该放在业务层。但是,实际情况并不尽然。个人认 为数据验证的方式,目前没有统一标准,可以根据需要放在表示层或业务层。但是,我个人不提倡在“表示层的服务端”放置过多完整性验证。因为,表示层的职责 应该仅仅是接收数据并传递给业务层,不应对数据是否合法负责。过多的数据验证,不但令表示层代码臃肿,而且使得表示层职责变得不明确。
可以在“表示层的服务端”放置一些简单的验证,如空值验证,两次输入密码是否一致等,但业务关系紧密的验证,最好放在业务层。甚至有些验证只能在业务层验 证,如“当前用户名不能与已有用户名重复”,这种验证需要访问持久化数据,需要由业务层完成。
这里之所以强调“表示层的服务端”,是因为一般在B/S系统中,都会在JavaScript里加入一些基本的数据验证,如空值检查,格式正则匹配等。这主 要是为了减轻服务器负担,将大多数显然包含不合法数据的请求拒绝掉,而不发给服务端验证。当然,因为可能会出现JS被屏蔽或黑客恶意攻击行为,所以,所有 验证不论JS中是否验证过,服务端(可能是表示层的服务端部分或业务层)一定要再进行验证。
2.3.3、CRUD
CRUD,即常说的增删改查操作。关于CRUD是否是业务层的职责,一直也是争议不断。因为目前并没有权威的定义,所以这里我斗胆说一下我对这个问题的看 法。还请大家批判性阅读。
一说到“增删改查”,大家一定会觉得这理所当然是数据访问层的职责。我认为这个理解是对的,但是只对了一半!之所以这么说,是因为“增删改查”有两个层次 含义。
第一个层次,是数据访问层次上的。在这个层次上,“增删改查”只是单纯的数据库操作,“增删改查”可以理解为“插入一条记录,删除一条记录,更新一条记录 的信息,获取一条或多条记录”四个操作,其意义和着眼点完全是数据访问层面上的,不带有任何业务成分和业务知觉。这个层面上的CRUD应该属于数据访问层 的职责。
第二个层次,是业务逻辑层次上的。在这个层次上,“增删改查”是业务领域内实体的变化以及一系列相关反应,“增删改查”可以理解为“领域内新增一个业务实 体,领域内去掉一个业务实体,领域内一个业务实体更新了信息,得到领域内一个或多个业务实体的信息”。
两者最大的不同,是业务层面上的增删改查往往不是单纯的增加减少,还包括实体变化后相关的业务流程。下面举个例子:
“添加一个新的订单”——这是一条典型的“增”操作。在数据访问层面上,它的意义是“在表示订单的数据表里增加一条记录”;而在业务逻辑层面上,它的意义 除了“领域内多了一个订单实体”外,还可能包括“根据业务规则判断是否是重复下单,根据金额对下订单客户的等级做相应提升、发送Email和短信通知客户 等”。可以看到,业务层面上的“增”可能不仅是简单封装一个简单的插入记录,可能还要去做其他数据访问——提升用户等级,以及做一些非CRUD的业务操作 ——发送短信通知。
在许多稍微复杂的系统中,业务往往不仅仅是封装了一条数据访问操作,而是还有很多如计算等业务处理,一个业务操作期间可能要多次使用数据访问操作。退一步 说,即使某个业务仅仅封装了一条数据访问操作,其意义和层面也是不同的,在数据访问层面,仅仅是多了一条记录,而业务逻辑层面,是领域内多了一个业务实 体。也许其本质上都是往数据库插入一条记录,但人类的抽象思维可以将之在不同层面上区分,这也是人类思维层面的一种抽象能力的表现。例如,我们知道太阳升 起不过是地球自转使得从背阴面转到了向阳面,但当人们看日出时,很少有人会说“看!我们从背阴面转到向阳面了!”,我们会说“看!日出!”,这就是同一事 物的不同层次表现。
2.3.4、存储过程
也许是性能上的诱惑,许多人喜欢在数据库系统中写很复杂的存储过程。这样,许多业务操作就被写到存储过程中去了。我个人建议,除非对性能要求极高,否则最 好还是不要用存储过程实现业务。例如,在一般的系统中,某个业务操作可能需要1秒,而是用了存储过程只用0.1秒,看上去存储过程将效率提高了10倍。但 对大多数用户来说,1秒和0.1秒的差别并不大,但是这样做的话,业务会变得十分不容易维护。所以,我个人觉得,除非十分必要,还是不要用存储过程实现业 务。
3、业务逻辑的架构模式及实现
Martin Fowler在《Patterns of Enterprise Application Architecture》一书中,总结了四种企业应用中业务逻辑的组织方式 :Transcation Script,Domain Model,Table Module及Service Layer,另外,本书的第十章“Data Source Architecture Patterns”中包含一种模式——Active Record。结合软件体系结构的近期发展及个人的理解,我更倾向将Active Record归入业务逻辑的组织模式,而Service Layer应该不算做业务逻辑特有的模式,所以,在本文中,将介绍四种模式:Transcation Script,Table Module,Active Record及Domain Model。
3.1、Transction Script
3.1.1、概述
Transction Script(以下简称TS)是一种面向过程的业务逻辑组织方式。这里首先要强调一点,这里的Transction一词与数据库系统中表示“事务”的 Transction没有任何联系。TS是将领域中的业务分解为一个个业务过程,每个过程实现一项业务功能,具体到程序中,一个业务过程往往映射到一个方法。TS是完全面向 过程的业务组织模式,适合应用于业务逻辑较简单的场合。
应该说,我们见到的绝大多数系统都是以TS组织业务的。例如PetShop及Oxite等经典示例。有时为了方便维护,开发者会将同一领域实体相关的业务 方法集中到一个类中,这里虽然用到了领域实体和类的概念,但和面向对象没有任何关系,完全是面向过程的。
当使用TS时,可以不需要数据访问层,而是将数据操作执行代码(如执行SQL或存储过程的代码)直接嵌入在业务方法中,有时为了复用性和维护性可以编写一 个helper类封装数据库的操作。当然这并不是说TS不能配合数据访问层使用,但由于应用TS的场合一般业务非常简单,如果配合Repository或 ORM使用,业务逻辑层往往就会变得非常“瘦”,看起来仅仅是对数据访问层的封装。一般在需要支持多数据库的场合,要配合Repository和 Abstract Factory使用。
TS的示意图如下所示:
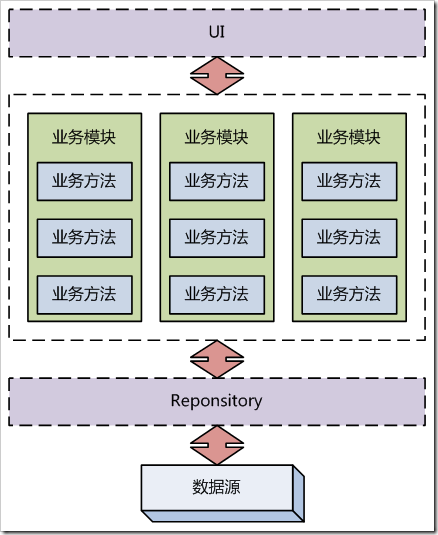
图3-1、 Transcation Script架构示意
可以看到,在TS中,业务层并没有面向对象的东西。也许会用到类,但类只是组织业务方法的模块,每个模块中有一个个业务方法,每个业务方法完成一个业务流 程,完全按面向过程结构组织。
3.1.2、分析
- 什么时候可以用TS?
应该说,如果具备以下条件之一 ,你可以考虑TS:
1)系统业务十分简单直观,并且频繁变动的可能性不大
2)工期很紧,需要尽量压缩设计的时间,尽快投入编码
3)不能熟练掌握和使用OO进行系统的设计与开发
4)厌恶OO,就是喜欢面向过程
- TS的优点?
1)设计阶段投入较小,启动耗费低。因为TS较容易掌握,使用起点低,所以使用TS的初期投入较少
2)在业务比较简单直观的情况下,TS结构的代码直观易懂,具有良好的可维护性
- TS的缺点?
1)容易造成代码冗余。因为各个业务自行组织流程,所以减少了复用的机会,可能产生重复性代码
2)因为TS天生不适合业务复杂的系统,当系统业务较复杂时,可能会令业务层代码繁杂不堪
3.2、Table Module
3.2.1、概述
Table Module(以下简称TM)同样是一种面向过程的业务逻辑组织方式,与TS不同的是,TM更贴近关系型数据库结构。在TS中,一般使用DTO等进行数据表示和传递,其着眼点一般在单个对象。而TM一般根 据数据表组织业务模块,每个模块对应一个表,其中包含了这个表的相应处理。并且在业务层内,使用库-表结构的对象进行数据操作,做到最大限度与数据表的对 应。业务组织一般按照面向过程组织。
一般当业务相对简单且业务基本集中在CRUD操作时,可以考虑TM。使用TM意味着使用数据驱动设计。通常自己实现一套库-表结构操作对象的库是难度比较 大的,所以一般选用TM时,所使用的平台应该包括这么一套库。如.NET平台上的ADO.net就内置了丰富的库-表操 作,DataSet,DataTable,DataAdapter等在TM架构的实现中可以起到非常方便的作用。
使用TM后,一般不需要再配合Reponsitory或ORM,因为此时的业务层也是面向过程和面向关系型结构的,无须映射。
TM的示意图如下:
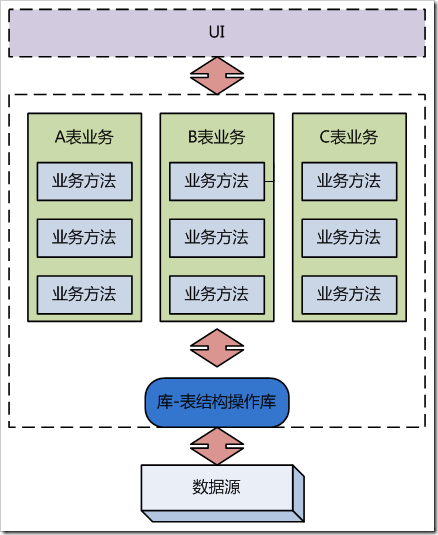
图3-2、Table Module架构示意
在使用TM后,业务代码中往往有各种对象对应数据库中的库、表、记录、字段等元素,并提供类似关系数据库的操作。
3.2.2、分析
- 什么时候可以用TM?
如果同时 具备以下条件,你可以考虑TM:
1)系统业务较直观,以CRUD操作比较集中
2)整个开发的指导思想是数据驱动
3)所选用的平台有成熟的库-表操作库支持
- TM的优点?
1)类似关系数据库的数据操作方式非常直观,使得设计和编写数据操作功能的代码简单高效
- TM的缺点?
1)TM需要完全的数据驱动,从业务到UI传递、存放数据都要以表结构形式,造成一定程度上的不灵活
2)当业务并非CRUD集中型操作,特别是领域模型和数据库表模型差异较大时,使用TM组织业务的难度非常大
3.3、Active Record
3.3.1、概述
Active Record(以下简称AR)是一种面向对象的业务逻辑组织方式。AR适用于在业务较简单的情况下,应用面向对象思想进行设计。它的基本思想就是将领域中每个实体抽象出一个业务类(BO),然后,将这个实体的数据和 行为封装成类的属性和方法。特别的,将CRUD功能也封装进BO中。也就是说,AR中的BO同时具备业务方法和持久化功能。其本身具有ORM的特性,其内 部要处理关系实体间的关联问题。
使用AR时,一般最好有相应框架支持,否则完全手工实现AR有点麻烦。像Castle框架中就有AR功能,Linq to sql也有AR的意思。使用AR后,一般不需要再单独使用数据访问层。
AR的组织架构如下图:
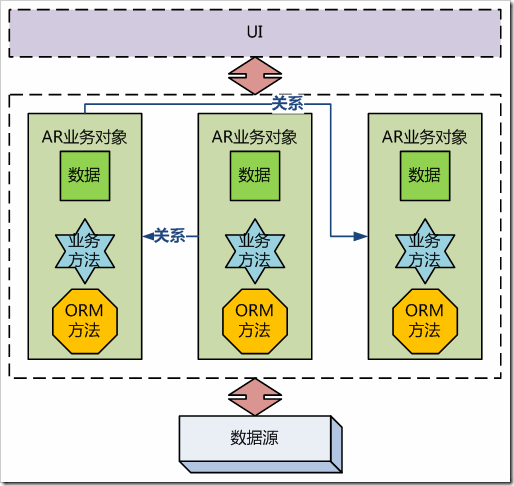
图3-3、Active Record架构示意
从图3-3中可以看出,AR对业务领域进行了一个简单的OO抽象,将各个实体抽象为AR业务对象,AR业务对象内含有数据、业务方法及数据访问相关的 ORM方法。另外,AR业务对象要维护实体间简单的一对多和多对多等关系。
3.3.2、分析
- 什么时候可以用AR?
如果同时 具备以下条件,你可以考虑AR:
1)系统业务较直观
2)想尝试使用或习惯于使用OO进行系统设计与实现
3)平台上有成熟的AR框架可以用
- AR的优点?
1)使用OO的方式进行设计与实现,能在一定程度上避免冗余代码问题)
2)使用AR后,与某个实体相关的数据和业务全部集中于AR业务对象中,模块内聚性好,便于维护
3)实践证明,AR结构的业务层编码效率很高
- AR的缺点?
1)AR仍需要关注数据之间的关联,在一定程度上带有数据表和影子,没有完全摆脱数据驱动,所以当业务领域和数据库结构差距大时,实施困难
2)AR的CRUD是以个体为粒度的,当进行批量操作时,如一次查数千个数据,如果严格尊从AR就需要生成数千个AR业务对象,这简直是场灾难。所以在有 大规模查询的情况下,可以考虑使用TS配合AR
3)如果业务非常复杂,AR将力不从心
3.4、Domain Model
3.4.1、概述
Domain Model(以下简称DM)是一种适合领域驱动和为复杂业务系统组织业务的面向对象业务逻辑组织方式。前面三种架构模式都有一个共同的缺点——不适合业务 复杂的系统。那么何为复杂何为简单?很抱歉,我给不出明确答案,而且我估计世界上任何一个人都很难给出标准的无争议答案。因为软件系统中的复杂和简单本身 就是一个难以量化的指标,很多时候,只能靠专业人员的经验了。
我个人估计,世界上95%的软件系统其业务难度都不会超出上述三种模式的能力范围,而若你不幸遇到剩下的5%,恐怕目前只有Domain Model能帮你了。Domain Model是一种纯面向对象的业务架构模式,它的核心思想是获取领域中的各种实体抽象,然后完全按照现实领域中的情况去建模和运行。并且业务对象是“持久 化无知”的。 关于“持久化无知”下面细讨论。这个模式十分复杂和难以掌握,但一旦掌握并使用,其能力绝对会超乎你的想象。
下面看一下DM的架构示意图:
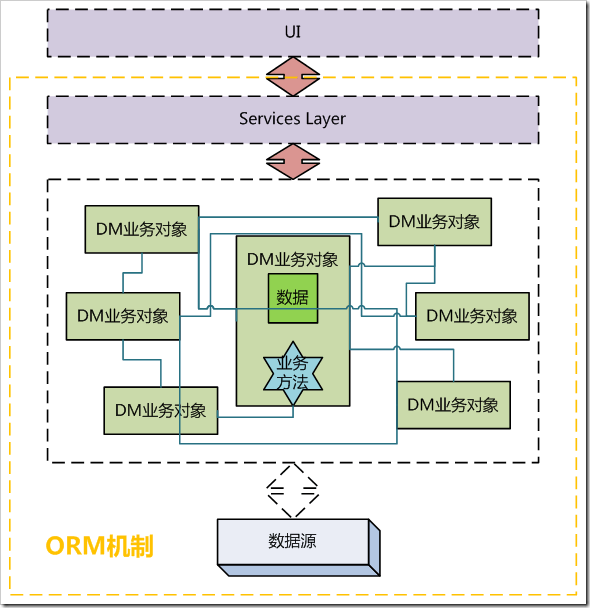
图3-4、 Domain Model架构示意
从图3-4中可以看出,DM看上去是个十分纠结的模式,而实际上,它确实很纠结!实际上,我认为如果能熟练掌握并运用DM进行业务逻辑的组织,那这人绝对 是架构师中的大师级人物(我目前是做不到)。
还是先结合图示分析一下DM中的要点。
第一,DM中的业务对象是纯业务对象,不含数据访问操作。这个可以和AR中的业务对象对比一下。也就是说,DM中的业务对象是纯业务对象,它们只关注与业 务的实现。
第二,DM的组织内部对象多,关系复杂,而这种关系不再只是那种简单的一对一、一对多的关系,而是领域中的各种依赖和关联的抽象,关系类型多,非常复杂。
第三,DM需要业务部分“持久化无知”。所谓持久化无知,指业务部分只需执行业务功能,而不必关系持久化。在使用DM时,必须设计一套ORM机制(注意这 里用到了“机制”一词,而不是“框架”或“库”),使得在业务系统运行时,自动在必要的时候执行数据持久化操作。这也是为什么上图数据源和业务层间的箭头 是虚线的关系。
上文曾说过,DM要最大程度模拟现实情况。而现实世界和软件世界最大的区别就是现实世界是“内存无限大、永不停机的”,可以把现实世界看成在一个无限大内 存里永不停止运行的程序。而软件世界不同,它的内存有限制,我们不能将所有对象都放在内存,而且一旦掉电,它就会停止运行,正因如此,我们才需要持久化机 制去配合DM模拟现实世界。为了让业务更接近现实,它必须对持久化过程毫无感觉。而一套持久化机制默默为其营造了一个好似内存无限大、永不停机的环境,因 此DM才得以发挥威力。
第四,DM往往需要Services Layer的配合。因为DM内部仅有一个个业务对象,它们互相调用,并没有提供一个友好的接口与UI交互,所以在使用DM时,往往在其上对各种UI需要的 服务进行封装(回顾一下Facade模式),形成一个Services Layer,以方便与UI交互。
3.4.2、分析
- 什么时候可以用DM?
如果同时 具备以下条件,你可以考虑DM:
1)系统业务极为复杂
2)有功底扎实和经验丰富的精通OO的架构及设计师
3)项目经费和时间充足
4)贯彻领域驱动设计
- DM的优点?
1)完全的OO思想运用,将使你享受到OO的所有优势
2)应付复杂业务的强力杀手锏。如果DM运用得当,将会使得复杂业务被高效解决
- DM的缺点?
1)使用门槛极高,难度极大,如果团队中没有精通OO和系统架构且经验丰富的专家很难实施
2)设计过程极为复杂,可能会导致设计瘫痪
3)如何设计良好的ORM机制辅助DM是一大难题
3.5、各种架构模式的比较及选择
相信看过上文内容后,各位一定对各种业务组织模式及其特点、优劣、应用场景有了清晰地认识,如果我在这里再喋喋不休讨论各种模式的比较及如何选择,难免有 侮辱各位智商之嫌O(∩_∩)O~,所以这里我只给大家呈现一幅决策网络图,以期起到一个梳理和归纳总结的作用。
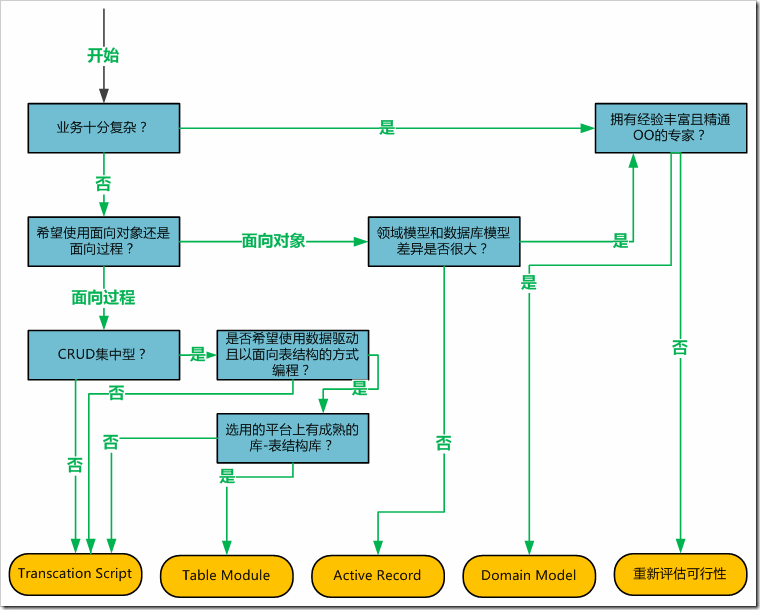
图3-5、业务架构模式决策网络
(郑重声明:图3-5为本人原创,并非摘录自已有文献,因此此图的选型流程仅代表个人意见。由于笔者水平有限,不能保证此图一定合理和正确。因此在实际选 型时请多多参考已有文献及咨询相关专家,此图只起总结归纳和探讨作用,不作为任何指导和规范。若因遵循此图选型而给项目带来的任何经济及其他方面损失,笔 者不承担任何责任。)
4、结束语
本文通过两篇文章的篇幅,先后介绍了业务逻辑的定义、相关理论及经典的业务逻辑相关的架构模式。本文中阐述了不少已有理论,亦掺杂诸多个人理解及看法。因 此请各位在阅读时多进行批判吸收,同时参考以后经典文献及书目综合理解业务逻辑,切勿仅看我一家之言。
另外,由于本文仅仅是综述性文章,不能具名业务逻辑的各个方面,在深度上也基本是浅尝辄止。因此,若希望深入理解业务逻辑,可以看到相关经典书籍及文献。
参考文献
[1] [意]Dino Esposito, Andrea Saltarello, .NET软件架构之美英文版(原名Microsoft .NET Architecting Application for the Enterprise), 人民邮电出版社, 2009
[2] [美]Martin Fowler, 企业应用架构模式影印版(原名Patterns of Enterprise Application Architecture), 中国电力出版社, 2004
[3] [美]Mclaughlin, Pollice, West, 深入浅出面向对象分析与设计影印版(原名Head First OOA&D), 东南大学出版社, 2007
[4] Google, www.google.com
关于socket阻塞与非阻塞情况下的recv、send、read、write返回值
原文地址:http://blog.csdn.net/eroswang/archive/2010/06/02/5642550.aspx
1、阻塞模式与非阻塞模式下recv的返回值各代表什么意思?有没有 区别?
(就我目前了解阻塞与非阻塞recv返回值没有区分,都是 <0:出错,=0:连接关闭,>0接收到数据大小,特别:返回值 < 0时并且(errno == EINTR || errno == EWOULDBLOCK || errno == EAGAIN)的情况下认为连接是 正常的,继续接收。只是阻塞模式下recv会阻塞着接收数据,非阻塞模式下如果没有数据会返回,不会阻塞着读,因此需要循环读取。
2、阻塞模式与非阻塞模式下write的返回值各代表什么意思? 有没有区别?
阻塞与非阻塞write返回值没有区分,都是 <0:出错,=0:连接关闭,>0发送数据大小,特别:返回值 <0时并且 (errno == EINTR || errno == EWOULDBLOCK || errno == EAGAIN)的情况下认为连接是正常的, 继续发送。只是阻塞模式下write会阻塞着发送数据,非阻塞模式下如果暂时无法发送数据会返回,不会阻塞着 write,因此需要循环发送。
3、阻塞模式下read返回 值 < 0 && errno != EINTR && errno != EWOULDBLOCK & amp;& errno != EAGAIN时,连接异常,需要关闭,read返回值 < 0 && amp; (errno == EINTR || errno == EWOULDBLOCK || errno == EAGAIN)时表示没有数据, 需要继续接收,如果返回值大于0表示接送到数据。
非阻塞模式下read返回值 < 0表示没有数据,= 0表示 连接断开,> 0表示接收到数据。
这2种模式下的返回值是不是这么理解,有没有更详细的理解或更准确的说明?
4、阻塞模式与非阻塞模式下是否send返回 值 < 0 && (errno == EINTR || errno == EWOULDBLOCK || errno == EAGAIN) 表示暂时发送失败,需要重试,如果send返回值 <= 0, && errno != EINTR && amp; errno != EWOULDBLOCK && errno != EAGAIN时,连接异常,需要关闭,如果send返回 值 > 0则表示发送了数据?send的返回值是否这么理解,阻塞模式与非阻塞模式下send返回值=0是否都是发送失败,还是那个模式下表示暂时 不可发送,需要 重发?
Oracle PL/SQL入门之慨述
一、PL/SQL出现的目的
结构化查询语言(Structured Query Language,简称SQL)是用来访问关系型数据库一种通用语言,它属于第四代语言(4GL),其执行特点是非过程化,即不用指明执行的具体方法和途径,而是简单的调用相应语句来直接取得结果即可。显然,这种不关注任何实现细节的语言对于开发者来说有着极大的便利。然而,对于有些复杂的业务流程又要求相应的程序来描述,那么4GL就有些无能为力了。PL/SQL的出现正是为了解决这一问题,PL/SQL是一种过程化语言,属于第三代语言,它与C,C++,Java等语言一样关注于处理细节,因此可以用来实现比较复杂的业务逻辑。
本教程分两部分,第一部分主要对PL/SQL的编程基础进行讨论,第二部分结合一个案例来讲解PL/SQL编程。希望读者阅读本文后能够对PL/SQL编程有一个总体上的认识,为今后深入PL/SQL编程打下一个基础。
二、PL/SQL编程基础
掌握一门编程语言首要是要了解其基本的语法结构,即程序结构、数据类型、控制结构以及相应的内嵌函数(或编程接口)。
1、PL/SQL程序结构
PL/SQL程序都是以块(block)为基本单位。如下所示为一段完整的PL/SQL块:
| /*声明部分,以declare开头*/ declare v_id integer; v_name varchar(20); cursor c_emp is select * from employee where emp_id=3; /*执行部分,以begin开头*/ begin open c_emp; --打开游标 loop fetch c_emp into v_id,v_name; --从游标取数据 exit when c_emp%notfound ; end loop ; close c_emp; --关闭游标 dbms_output.PUT_LINE(v_name); /*异常处理部分,以exception开始*/ exception when no_data_found then dbms_output.PUT_LINE('没有数据'); end ; |
从上面的PL/SQL程序段看出,整个PL/SQL块分三部分:声明部分(用declare开头)、执行部分(以begin开头)和异常处理部分(以exception开头)。其中执行部分是必须的,其他两个部分可选。无论PL/SQL程序段的代码量有多大,其基本结构就是由这三部分组成。
2、变量声明与赋值
PL/SQL主要用于数据库编程,所以其所有数据类型跟oracle数据库里的字段类型是一一对应的,大体分为数字型、布尔型、字符型和日期型。为方便理解后面的例程,这里简单介绍两种常用数据类型:number、varchar2。
number
用来存储整数和浮点数。范围为1E-130 ~10E125,其使用语法为:
| number[(precision, scale)] |
其中(precision, scale)是可选的,precision表示所有数字的个数,scale表示小数点右边数字的个数。
varchar2
用来存储变长的字符串,其使用语法为:
| varchar2[(size)] |
其中size为可选,表示该字符串所能存储的最大长度。
在PL/SQL中声明变量与其他语言不太一样,它采用从右往左的方式声明,比如声明一个number类型的变量v_id,那其形式应为:
| v_id number; |
如果给上面的v_id变量赋值,不能用”=”应该用”:=”,即形式为:
| v_id :=5; |
3、控制结构
PL/SQL程序段中有三种程序结构:条件结构、循环结构和顺序结构。
条件结构
与其它语言完全类似,语法结构如下:
| if condition then statement1 else statement2 end if ; |
循环结构
这一结构与其他语言不太一样,在PL/SQL程序中有三种循环结构:
| a. loop … end loop; b. while condition loop … end loop; c. for variable in low_bound . . upper_bound loop … end loop; |
其中的“…”代表循环体。
顺序结构
实际就是goto的运用,不过从程序控制的角度来看,尽量少用goto可以使得程序结构更加的清晰。
4、SQL基本命令
PL/SQL使用的数据库操作语言还是基于SQL的,所以熟悉SQL是进行PL/SQL编程的基础。表1-1为SQL语言的分类。
表1-1 SQL语言分类
| 类别 | SQL语句 |
| 数据定义语言(DDL) | Create ,Drop,Grant,Revoke, … |
| 数据操纵语言(DML) | Update,Insert,Delete, … |
| 数据控制语言(DCL) | Commit,Rollback,Savapoint, … |
| 其他 | Alter System,Connect,Allocate, … |
三、过程与函数
PL/SQL中的过程和函数与其他语言的过程和函数的概念一样,都是为了执行一定的任务而组合在一起的语句。过程无返回值,函数有返回值。其语法结构为:
过程:Create or replace procedure procname(参数列表) as PL/SQL语句块
函数:Create or replace function funcname(参数列表) return 返回值 as PL/SQL语句块
这里为了更为方面的说明过程的运用,下面给出一个示例:
问题:假设有一张表t1,有f1和f2两个字段,f1为number类型,f2为varchar2类型,然后往t1里写两条记录,内容自定。
| Create or replace procedure test_procedure as V_f11 number :=1; /*声明变量并赋初值*/ V_f12 number :=2; V_f21 varchar2(20) :=’first’; V_f22 varchar2(20) :=’second’; Begin Insert into t1 values (V_f11, V_f21); Insert into t1 values (V_f12, V_f22); End test_procedure; /*test_procedure可以省略*/ |
至此,test_procedure存储过程已经完成,然后经过编译后就可以在其他PL/SQL块或者过程中调用了。由于函数与过程具有很大的相似性,所以这里就不再重复了。
四、游标
这里特别提出游标的概念,是因为它在PL/SQL的编程中非常的重要。其定义为:用游标来指代一个DML SQL操作返回的结果集。即当一个对数据库的查询操作返回一组结果集时,用游标来标注这组结果集,以后通过对游标的操作来获取结果集中的数据信息。定义游标的语法结构如下:
| cursor cursor_name is SQL语句; |
在本文第一段代码中有一句话如下:
| cursor c_emp is select * from employee where emp_id=3; |
其含义是定义一个游标c_emp,其代表着employee表中所有emp_id字段为3的结果集。当需要操作该结果集时,必须完成三步:打开游标、使用fetch语句将游标里的数据取出、关闭游标。请参照本文第一段代码的注释理解游标操作的三步骤。
五、其他概念
PL/SQL中包的概念很重要,主要是对一组功能相近的过程和函数进行封装,类似于面向对象中的名字空间的概念。
触发器是一种特殊的存储过程,其调用者比较特殊,是当发生特定的事件才被调用,主要用于多表之间的消息通知。
六、调试环境
PL/SQL的调试环境目前比较多,除了Oracle自带有调试环境Sql*plus以外,本人推荐TOAD这个工具,该工具用户界面友好,可以提高程序的编制效率。
Linux C函数之时间函数
asctime
ctime
gettimeofday
gmtime
localtime
mktime
settimeofday
time
|
|
|
|
相关函数 |
time,ctime,gmtime,localtime |
|
表头文件 |
#include<time.h> |
|
定义函数 |
char * asctime(const struct tm * timeptr); |
|
函数说明 |
asctime()将参数timeptr所指的tm结构中的信息转换成真实世界所使用的时间日期表示方法,然后将结果以字符串形态返回。此函数已经由时区转换成当地时间,字符串格式为:“Wed Jun 30 21:49:08 1993\n” |
|
返回值 |
若再调用相关的时间日期函数,此字符串可能会被破坏。此函数与ctime不同处在于传入的参数是不同的结构。 |
|
附加说明 |
返回一字符串表示目前当地的时间日期。 |
|
范例 |
#include <time.h> |
|
执行 |
Sat Oct 28 02:10:06 2000 |
|
|
|
|
相关函数 |
time,asctime,gmtime,localtime |
|
表头文件 |
#include<time.h> |
|
定义函数 |
char *ctime(const time_t *timep); |
|
函数说明 |
ctime()将参数timep所指的time_t结构中的信息转换成真实世界所使用的时间日期表示方法,然后将结果以字符串形态返回。此函数已经由时区转换成当地时间,字符串格式为“Wed Jun 30 21 :49 :08 1993\n”。若再调用相关的时间日期函数,此字符串可能会被破坏。 |
|
返回值 |
返回一字符串表示目前当地的时间日期。 |
|
范例 |
#include<time.h> |
|
执行 |
Sat Oct 28 10 : 12 : 05 2000 |
|
|
|
|
相关函数 |
time,ctime,ftime,settimeofday |
|
表头文件 |
#include <sys/time.h> |
|
定义函数 |
int gettimeofday ( struct timeval * tv , struct timezone * tz ) |
|
函数说明 |
gettimeofday()会把目前的时间有tv所指的结构返回,当地时区的信息则放到tz所指的结构中。 |
|
返回值 |
成功则返回0,失败返回-1,错误代码存于errno。附加说明EFAULT指针tv和tz所指的内存空间超出存取权限。 |
|
范例 |
#include<sys/time.h> |
|
执行 |
tv_sec: 974857339 |
|
|
|
|
相关函数 |
time,asctime,ctime,localtime |
|
表头文件 |
#include<time.h> |
|
定义函数 |
struct tm*gmtime(const time_t*timep); |
|
函数说明 |
gmtime()将参数timep 所指的time_t 结构中的信息转换成真实世界所使用的时间日期表示方法,然后将结果由结构tm返回。 |
|
返回值 |
返回结构tm代表目前UTC 时间 |
|
范例 |
#include <time.h> |
|
执行 |
|
|
|
|
|
相关函数 |
time, asctime, ctime, gmtime |
|
表头文件 |
#include<time.h> |
|
定义函数 |
struct tm *localtime(const time_t * timep); |
|
函数说明 |
localtime()将参数timep所指的time_t结构中的信息转换成真实世界所使用的时间日期表示方法,然后将结果由结构tm返回。结构tm的定义请参考gmtime()。此函数返回的时间日期已经转换成当地时区。 |
|
返回值 |
返回结构tm代表目前的当地时间。 |
|
范例 |
#include<time.h> |
|
执行 |
|
|
|
|
|
相关函数 |
time,asctime,gmtime,localtime |
|
表头文件 |
#include<time.h> |
|
定义函数 |
time_t mktime(strcut tm * timeptr); |
|
函数说明 |
mktime()用来将参数timeptr所指的tm结构数据转换成从公元 |
|
返回值 |
返回经过的秒数。 |
|
范例 |
/* 用time()取得时间(秒数),利用localtime() |
|
执行 |
time():974943297 |
|
|
|
|
相关函数 |
time,ctime,ftime,gettimeofday |
|
表头文件 |
#include<sys/time.h> |
|
定义函数 |
int settimeofday ( const struct timeval *tv,const struct timezone *tz); |
|
函数说明 |
settimeofday()会把目前时间设成由tv所指的结构信息,当地时区信息则设成tz所指的结构。详细的说明请参考gettimeofday()。注意,只有root权限才能使用此函数修改时间。 |
|
返回值 |
成功则返回0,失败返回-1,错误代码存于errno。 |
|
错误代码 |
EPERM 并非由root权限调用settimeofday(),权限不够。 |
|
|
|
|
相关函数 |
ctime,ftime,gettimeofday |
|
表头文件 |
#include<time.h> |
|
定义函数 |
time_t time(time_t *t); |
|
函数说明 |
此函数会返回从公元1970年1月1日的UTC时间从0时0分0秒算起到现在所经过的秒数。如果t 并非空指针的话,此函数也会将返回值存到t指针所指的内存。 |
|
返回值 |
成功则返回秒数,失败则返回((time_t)-1)值,错误原因存于errno中。 |
|
范例 |
#include<time.h> |
|
执行 |
9.73E+08 |